The First 5 Minutes of an Outage: A Response Playbook
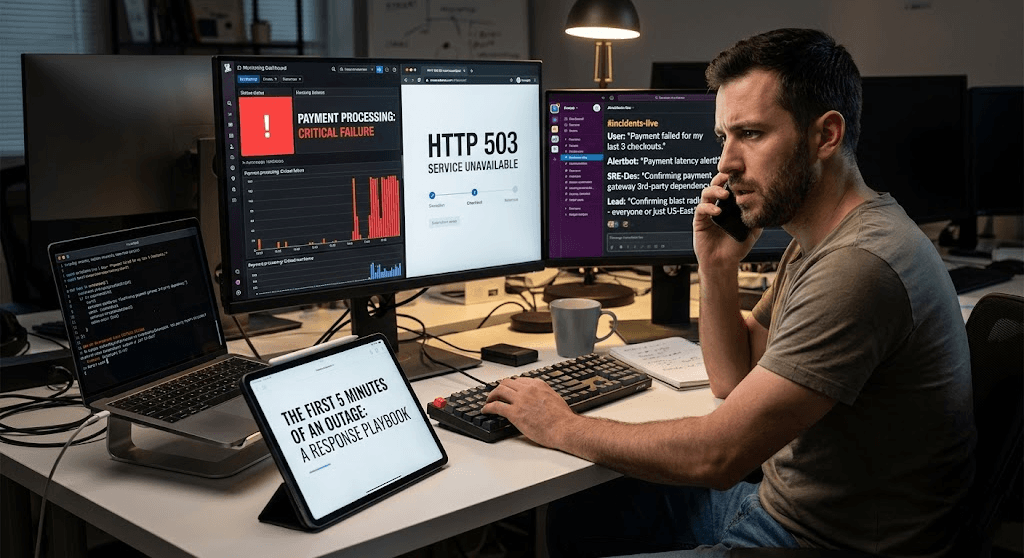
Seu provedor de pagamento acabou de falhar. Os clientes não conseguem finalizar a compra. O que você faz primeiro?
A diferença entre um incidente de 10 minutos e um pesadelo de 2 horas geralmente se resume ao que acontece nos primeiros 300 segundos. A maioria das equipes desperdiça esses minutos preciosos em confusão, apontando dedos ou perseguindo os sinais errados.
Já vi isso acontecer vezes suficientes para escrever a respeito.
Por que os primeiros 5 minutos realmente importam
A equipe de SRE do Google descobriu que o MTTD e a qualidade da resposta inicial respondem por mais de 60% da duração total de um incidente. No entanto, a maioria dos runbooks foca na resolução — e não na realidade caótica e movida a adrenalina daqueles primeiros momentos, quando o Slack explode e ninguém sabe quem está no comando.
Eis o que normalmente dá errado:
- Várias pessoas investigando a mesma coisa
- Ninguém assume a coordenação
- As equipes depuram sintomas em vez de confirmar a falha real
- Dependências externas são culpadas sem verificação
- A comunicação com stakeholders é atrasada ou caótica
Eis o que fazer em vez disso.
Minuto 0–1 — Confirme, não presuma
Antes de mergulhar nos logs, responda três perguntas:
- Isso é real? Verifique se várias fontes de monitoramento concordam. Um único alerta pode ser um falso positivo.
- Qual é o raio de impacto? Um usuário, uma região ou todo mundo?
- É culpa nossa ou deles? Verifique suas dependências de terceiros imediatamente.
No mês passado, uma startup de fintech passou 45 minutos depurando seu fluxo de checkout antes de perceber que a API do provedor de pagamento estava com taxas de erro elevadas em eu-west-1. Uma única olhada no dashboard certo teria poupado 40 minutos de estresse desnecessário.
Antes de seguir adiante, você deve ter:
- ☐ Alerta confirmado por uma segunda fonte
- ☐ Raio de impacto identificado (% de usuários afetados)
- ☐ Páginas de status de terceiros verificadas
- ☐ Severidade inicial atribuída (SEV1 / SEV2 / SEV3)
Minuto 1–2 — Alguém precisa estar no comando. Agora.
A frase mais perigosa na resposta a incidentes: "Achei que outra pessoa estava cuidando disso."
Designe dois papéis imediatamente:
- Incident Commander (IC) — coordena a resposta, toma decisões, comunica para fora
- Technical Lead — depuração prática, propõe e implementa correções
Em equipes pequenas, uma pessoa pode acumular os dois papéis — mas deixe isso explícito. Poste no seu canal de incidente:
🚨 INCIDENTE DECLARADO — SEV2
IC: @maria
Tech Lead: @james
Problema: Falhas no checkout — investigando se está relacionado ao provedor de pagamento
Status: Confirmando escopo
Próxima atualização: 5 minutos
- ☐ Incident Commander designado
- ☐ Technical Lead designado
- ☐ Canal de incidente criado ou identificado
- ☐ Mensagem inicial postada com definição de responsabilidade
Minuto 2–3 — Reúna contexto rápido
Você tem 60 segundos. Escolha as perguntas certas:
| Pergunta | Ação | |----------|------| | O que mudou? | Verifique os deployments das últimas 2 horas | | Quando começou? | Correlacione com suas métricas | | Qual é o erro? | Capture a mensagem/código de erro real | | Quem foi afetado? | Segmente por região, plano ou tipo de cliente |
Se você monitora dependências proativamente, muitas vezes recebe alertas antes que suas próprias taxas de erro disparem — o que reduz o MTTD em 8 a 12 minutos só por saber primeiro que um terceiro está degradado.
- ☐ Deployments recentes revisados
- ☐ Horário de início do incidente identificado
- ☐ Mensagem de erro principal capturada
- ☐ Segmento de usuários afetados identificado
Minuto 3–4 — Comunique cedo. O silêncio é seu inimigo.
Seus clientes, sua equipe de suporte e seus executivos estão todos se perguntando: será que eles ao menos sabem que existe um problema?
Envie uma atualização mesmo sem respostas.
Interno (Slack / Teams):
⚠️ ATUALIZAÇÃO DE INCIDENTE — Minuto 3
Status: Investigando
Impacto: ~15% das tentativas de checkout falhando
Causa: Sob investigação — verificando integração com provedor de pagamento
ETA: Desconhecido — próxima atualização em 5 min
Externo (página de status):
Investigando — Problemas no Checkout
Estamos investigando relatos de falhas em tentativas de checkout. Alguns
clientes podem encontrar erros ao concluir compras. Nossa equipe está
trabalhando ativamente nisso. Atualizações em breve.
- ☐ Stakeholders internos notificados
- ☐ Equipe de suporte alertada com pontos de comunicação iniciais
- ☐ Página de status atualizada
- ☐ Horário da próxima atualização comprometido
Minuto 4–5 — Estanque o sangramento antes da cirurgia
Seu objetivo agora não é a causa raiz. É reduzir o impacto.
| Problema | Ação | |----------|------| | Deployment ruim | Rollback | | Terceiro fora do ar | Habilitar fallback / circuit breaker | | Pico de tráfego | Escalar ou aplicar rate limit | | Sobrecarga de banco de dados | Encerrar queries de longa duração | | Desconhecido | Desligar a área afetada via feature flag |
Eis um padrão básico de circuit breaker caso o provedor de pagamento seja o culpado:
const paymentCircuitBreaker = {
isOpen: false,
failureCount: 0,
threshold: 5,
async call(operation) {
if (this.isOpen) return this.fallback();
try {
const result = await operation();
this.reset();
return result;
} catch (error) {
this.failureCount++;
if (this.failureCount >= this.threshold) {
this.isOpen = true;
this.scheduleReset();
}
throw error;
}
},
fallback() {
return { status: 'queued', message: 'Processing your payment...' };
}
};
- ☐ Ação de mitigação decidida
- ☐ Mitigação implementada ou em andamento
- ☐ Trajetória de impacto avaliada (melhorando / piorando / estável)
- ☐ Plano de acompanhamento de 10 minutos estabelecido
O checklist completo, em uma tela
- 0–1 · Confirmar — alerta verificado, raio de impacto conhecido, terceiros checados, severidade atribuída
- 1–2 · Assumir — IC designado, tech lead designado, canal ativo, primeira mensagem postada
- 2–3 · Contexto — mudanças recentes revisadas, horário de início identificado, erro capturado, segmento identificado
- 3–4 · Comunicar — atualização interna enviada, suporte informado, página de status no ar, próxima atualização agendada
- 4–5 · Estabilizar — mitigação decidida, mitigação em andamento, trajetória avaliada, plano de acompanhamento definido
Cenário real: a queda do Twilio que não foi culpa sua
14:34 — Alertas de erro disparam. Verificação por SMS falhando em 30% das tentativas de login.
14:35 — Engenheiro verifica o dashboard de monitoramento. API de SMS do Twilio apresentando desempenho degradado na região. Alívio imediato: não é o nosso código.
14:36 — Incidente declarado. IC designado. Mensagem postada: "Degradação de SMS do Twilio confirmada. Investigando opções de fallback."
14:37 — Contexto reunido: a página de status do Twilio confirma problemas desde 14:31. Sem ETA.
14:38 — Equipe de suporte notificada: "Estamos cientes dos atrasos de SMS. Verificação por e-mail disponível como alternativa."
14:39 — Fallback habilitado: 2FA por e-mail ativado. Circuit breaker aberto no caminho de SMS.
Impacto total voltado ao cliente: 5 minutos — em vez dos 47 minutos que o Twilio levou para resolver completamente.
Essa é a diferença que os primeiros 5 minutos fazem.
30-day free trial
Never miss an API outage again.
Monitor 1,000+ APIs from 4 global regions. Get alerted on Slack, email or webhooks before your users notice. Free for 30 days on Indie.
Start free trialRelated API
Stripe Invoices
Related Posts

Comments
Sign in to join the conversation and leave a comment.
Sign In to Comment